
Australian Open 2019: Il Lucky Index

Come accade ogni anno il sorteggio dei tabelloni di uno Slam si porta dietro le inevitabili polemiche che possono scaturire da una estrazione a sorte che per sua natura si porta dietro una componente di aleatorietà. La soluzione più logica per ovviare alle polemiche sarebbe quello di usare 128 tds determinate dal ranking ATP. Ogni slot sarebbe ben definito prima del sorteggio che a questo punto diventerebbe inutile. Non ci sarebbero problemi per le wildcard e/o i qualificati perché, essendo dotati anche loro di ranking ATP, andrebbero ad occupare una precisa posizione. Però bisogna andare al di là dell’utopia e valutare quanto più oggettivamente quello che succede e non come dovrebbe essere.
L’obiettivo di questo articolo è quello di stabilire nella maniera più oggettiva possibile chi è stato maggiormente “fortunato” nel sorteggio. Le considerazioni su questo particolare argomento vengono espletate in maniera semplicistica basandosi su considerazioni derivanti da verità soggettive che spesso solo edulcorate dal proprio tifo. Quindi, per poter essere obiettivi bisogna superare questi limiti e usare i numeri. Innanzitutto, partiamo dai dati certi che spesso vengono trascurati. Con 32 teste di serie lo schema del sorteggio è il seguente:
- Al 3T: 1-8 vs 25-32 e 9-16 vs 17-24
- Al 4T: 1-4 vs 13-16 e 5-8 vs 9-12
- Ai QF 1-4 vs 5-8
- In SF 1-2 vs 3-4
- In F 1-2
Questo significa che prima del 3° turno le teste di serie non si possono incontrare, di conseguenza è banale e inutile dire che nei primi turni i migliori hanno pescato i peggiori. Magari può capitare di beccare l’outsider che per un motivo o un altro è finito fuori dal lotto dei 32, ma è solo un caso. Quindi, non solo caso, ma uno. Bisogna considerare tutte le possibili combinazioni per i 7 turni possibili. Ed ecco che magari un 1° turno facile corrisponde con un probabile 4° turno difficile, per esempio. Come uscire da questa impasse? Manipoliamo degli strumenti che già abbiamo in modo da arrivare al goal.
Lo strumento da usare è quello già usato in questo articolo. È essenziale che i concetti riportati lì siano chiari altrimenti è inutile continuare. Si potrebbero riportare qui però allungherebbe molto il discorso, discorso che dovrebbe già essere chiaro. (Si consiglia vivamente di rileggerlo).
Il punto cruciale di quelle simulazioni è che si basano sostanzialmente su un numero che quantifica la “potenza istantanea” di quel tennista. È molto semplicistico usare un solo numero per poter dire quanto è forte un tennista in quel momento e soprattutto usare questo numero per simulare uno scontro con un altro. Nelle simulazioni in cui l’Head-to-Head è fondamentale, vedasi betting, subentrano altre componenti che quantificano quanto un tennista sia più forte rispetto all’avversario non solo in base a quello che ha fatto fino a quel momento, ma basandosi anche e soprattutto sui precedenti (H2H) tra i tennisti che devono disputare una partita. Qui non sarà usato questo accorgimento per diversi motivi, quello principale è che non esiste un metodo unico e oggettivo, per cu si dovrebbe usare un metodo nel metodo per arrivare al goal, un po’ troppo macchinoso, anche se inevitabilmente aumenterebbe la qualità del lavoro svolto.
Non ci rimane che rintracciare i dati che ci servono, però qui c’è un bivio: quale “numeri” usare? Quelli del J-Rank sono precisi e dettagliati e per certi versi molto più attendibili del ranking ATP però, come tutti gli aggiustamenti non ufficiali, si porta dietro una componente soggettiva che non sempre trova consenso unanima in chi legge e vuole usare il metodo sviluppato in maniera indipendente. Per questo motivo, nella simulazione si sceglieranno i punti del ranking ATP per determinare la forza di un tennista. Il sorteggio del tabellone degli Australian Open 2019 ha dato il suo responso:
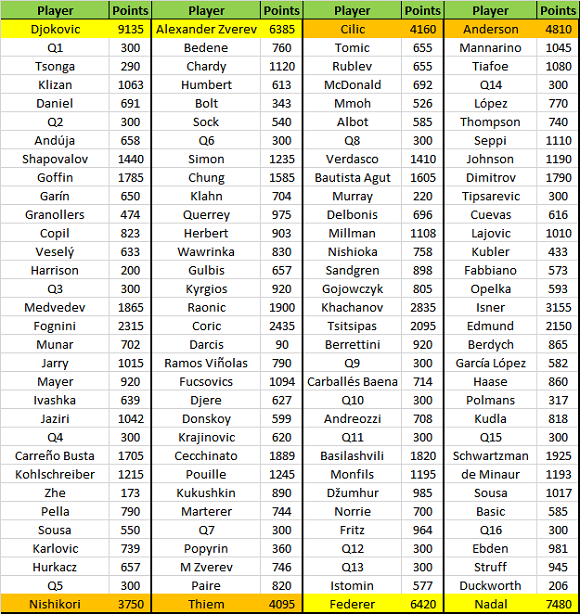
Finora tutto normale. Se le simulazioni con questi dati implementate fino a oggi ci dicono in termini di percentuale quanto è la probabilità di vincere il torneo (in realtà quella di raggiungere tutti i turni) quale metodo usare per determinarne la fortuna? Semplice: sostituiamo ad ogni tennista il ranking medio in modo tale che tutti si trovino sullo stesso piano, con la stessa forza e vediamo quali sono le sue possibilità di vincere il torneo. Sembra scontato dire che le possibilità dipenderanno sempre e comunque da qui c’è intorno nel tabellone ma non più dalla propria forza che in questo caso è rappresentata da una forza media uguale per tutti. Così è possibile stilare una classifica basandoci su un indice di fortuna, lucky index. Come è facile intuire la classifica è valida solo per confrontare la fortuna dei tennisti appartenenti alla stessa fascia. Le prime 2 teste di serie si trovano sullo stesso piano e la simulazione ci dice che x è stato più fortunato di y. Può capire anche che ci sia uno scambio di fasce, questo perché anche per una testa di serie relativamente bassa ci può essere maggiore fortuna rispetto a chi sta più in alto. La tabella dei lucky index per ognuno dei 128 partecipanti è riportata qui:
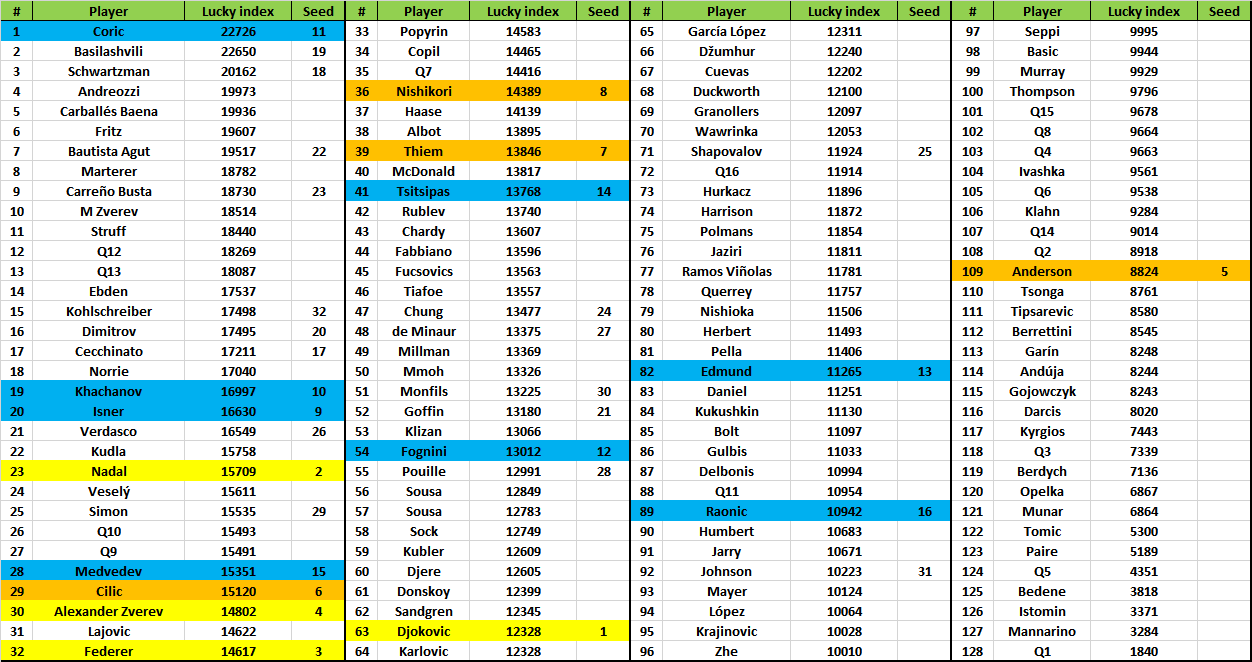

Premessa: basandoci su una simulazione Monte Carlo non è possibile avere sempre gli stessi numeri. Per avere un numero deterministico occorrono 1.072*10^38 simulazioni di tabellone. Impiegheremmo milioni di anni per avere un output anche con il computer più sofisticato del mondo. Il metodo Monte Carlo serve proprio a questo, ossia a dare una buonissima approssimazione anche con un numero molto inferiore di simulazioni rispetto al caso perfetto. Nel programma di Sackmann le simulazioni sono 100.000 e danno un output (su PC commerciale) dopo qualche secondo. Il numero è stato settato a 10.000.000 per avere una stima molto più attendibile (con qualche ora di simulazione).
Il numerino che si vede, i.e. 22.726 per Coric non vuol dire nulla di per sé, rappresenta il numero di volte che il giocatore ha vinto il torneo nella simulazione. L’aspetto più importante è capire solo chi è stato più fortunato rispetto ad un altro, non quanto è stato più fortunato, definizione che trova poca consistenza anche nel gergo colloquiale. Nessuno si sognerebbe di dire che Tizio è stato 5.6% più fortunato di Caio, ma piuttosto che Tizio è stato più fortunato di Caio.
Leggiamo i dati.Il più fortunato del tabellone risulta Borna Coric, testa di serie numero 11, e inserito in uno spicchio di tabellone piuttosto agevole. Il primo avversario serio dovrebbe essere Thiem, ma solo al quarto turno.
Tra i primi 4 della classe Nadal risulta essere il più fortunato con ampio margine su Alex Zverev e Federer che risultano appaiati. Molto distante e “sfortunato” Novak Djokovic con un tabellone piuttosto duro fin dalle prime battute. Il più sfortunato del lotto risulta Kevin Anderson che, nonostante la tds 5 è al 109° posto della classifica di Lucky Index. Il più sfortunato di tutti sarà il qualificato che incontrerà Djokovic nel primo turno.